



原标题:快速玩转 Mixtral 8x7B MOE大模型!阿里云机器学习 PAI 推出最佳实践
Mixtral 8x7B大模型是Mixtral AI推出的基于decoder-only架构的稀疏专家混合网络(Mixture-Of-Experts,MOE)开源大语言模型。这一模型具有46.7B的总参数量,对于每个token,路由器网络选择八组专家网络中的两组做处理,并且将其输出累加组合,在增加模型参数总量的同时,优化了模型推理的成本。在大多数基准测试中,Mixtral 8x7B模型与Llama2 70B和GPT-3.5表现相当,因此具备极高的使用性价比。
阿里云人工智能平台PAI是面向开发者和企业的机器学习/深度学习平台,提供包含数据标注、模型构建、模型训练、模型部署、推理优化在内的AI开发全链路服务。
本文介绍如何在PAI平台针对Mixtral 8x7B大模型的微调和推理服务的最佳实践,助力AI开发者快速开箱。以下我们将分别展示具体使用步骤。
PAI-DSW是云端机器学习开发IDE,为用户更好的提供交互式编程环境,同时提供了丰富的计算资源。我们在智码实验室()Notebook Gallery中上线了两个微调Mixtral 8x7B MOE大模型的示例,参见下图:

上述Notebook能够正常的使用阿里云PAI-DSW的实例打开,并且要选择对应的计算资源和镜像。
Swift是魔搭ModelScope开源社区推出的轻量级训练推理工具开源库,使用Swift进行这一大模型LoRA轻量化微调需要用2张A800(80G)及以上资源。在安装完对应依赖后,我们第一步下载模型至本地:
模型训练完成后,我们将学习到的LoRA权重合并到模型Checkpoint中:
其中,ckpt_dir参数的值需要替换成模型LoRA权重保存路径。为了测试模型训练的正确性,我们大家可以使用transformers库进行离线推理测试:
我们也能够正常的使用Deepspeed对Mixtral 8x7B MOE大模型进行LoRA轻量化微调。同样的,我们应该使用2张A800(80G)及以上资源。我们第一步下载模型至本地:
第二步,我们下载一个示例古诗生成数据集,用户都能够根据下述数据格式准备自己的数据集。
如果用户要将上述模型部署为EAS服务,需要将格式转换成safetensors格式:
PAI-EAS是PAI平台推出的弹性推理服务,可以将各种大模型部署为在线服务。当Mixtral 8x7B MOE大模型微调完毕后,我们大家可以将其部署为PAI-EAS服务。这里,我们介绍使用PAI-SDK将上述模型进行部署。首先,我们在PAI-DSW环境安装PAI-SDK:
在安装完成后,在在命令行终端上执行以下命令,按照引导完成配置AccessKey、PAI工作空间以及 OSS Bucket:
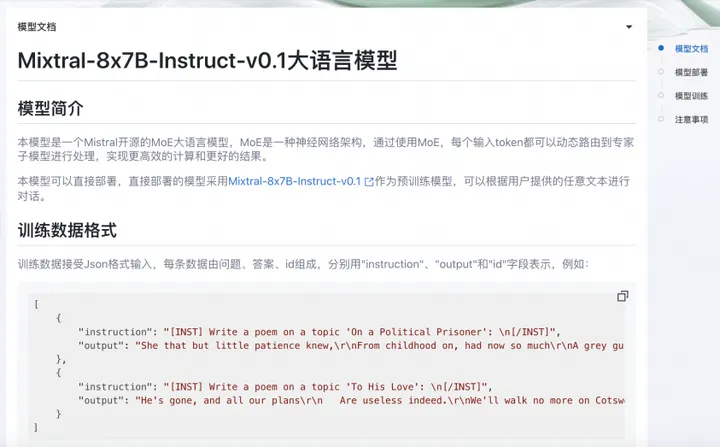
快速开始(PAI-QuickStart)集成了国内外AI开源社区中优质的预训练模型,支持零代码实现微调和部署Mixtral 8x7B MOE大模型,用户只应该要依据格式上传训练集和验证集,填写训练时候使用的超参数就可以一键拉起训练任务。Mixtral的模型卡片如下图所示:
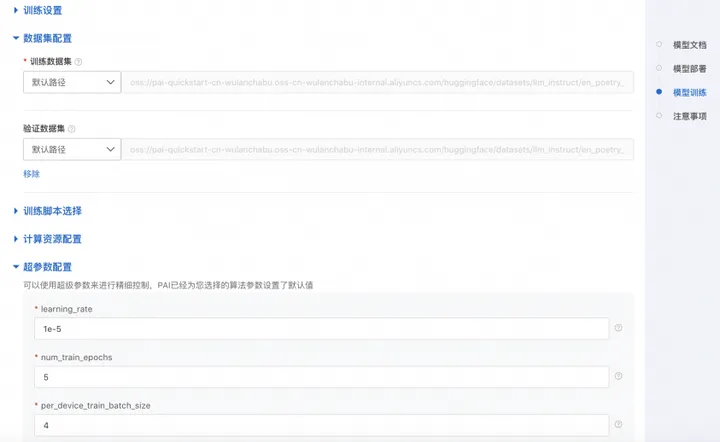
点击“训练”按钮,PAI-QuickStart开始做训练,用户都能够查看训练任务状态和训练日志,如下所示:
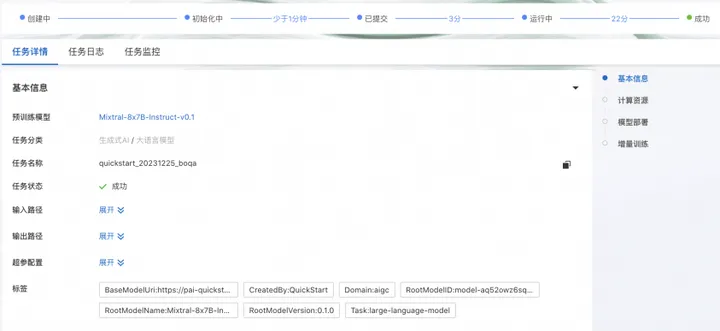
如果需要将模型部署至PAI-EAS,可以在同一页面的模型部署卡面选择资源组,并且点击“部署”按钮实现一键部署。模型调用方式和上文PAI-EAS调用方式相同。
